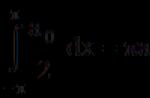Yang menemukan aplikasi terluas di berbagai bidang sains dan praktik. Bisa fisika, kimia, biologi, ekonomi, sosiologi, psikologi dan lain sebagainya. Dengan kehendak takdir, saya sering harus berurusan dengan ekonomi, dan karena itu hari ini saya akan mengaturkan Anda tiket ke negara yang menakjubkan bernama ekonometrika=) … Bagaimana Anda tidak menginginkannya?! Sangat bagus di sana - Anda hanya perlu memutuskan! …Tapi yang mungkin Anda inginkan adalah belajar bagaimana memecahkan masalah kuadrat terkecil. Dan terutama pembaca yang rajin akan belajar menyelesaikannya tidak hanya secara akurat, tetapi juga SANGAT CEPAT ;-) Tapi pertama-tama pernyataan umum dari masalah+ contoh terkait:
Biarkan indikator dipelajari di beberapa bidang studi yang memiliki ekspresi kuantitatif. Pada saat yang sama, ada banyak alasan untuk percaya bahwa indikator bergantung pada indikator. Asumsi ini dapat berupa hipotesis ilmiah dan berdasarkan akal sehat dasar. Namun, mari kita kesampingkan sains, dan jelajahi area yang lebih menggugah selera - yaitu, toko kelontong. Dilambangkan dengan:
– ruang ritel toko kelontong, sq.m.,
- omset tahunan toko kelontong, juta rubel.
Cukup jelas bahwa semakin besar area toko, semakin besar omsetnya dalam banyak kasus.
Misalkan setelah melakukan pengamatan / eksperimen / perhitungan / menari dengan rebana, kami memiliki data numerik yang kami miliki: 
Dengan toko kelontong, saya pikir semuanya jelas: - ini adalah area toko pertama, - omset tahunannya, - area toko ke-2, - omset tahunannya, dll. Ngomong-ngomong, sama sekali tidak perlu memiliki akses ke materi rahasia - penilaian omset yang cukup akurat dapat diperoleh dengan menggunakan statistik matematika. Namun, jangan terganggu, kursus spionase komersial sudah dibayar =)
Data tabular juga dapat ditulis dalam bentuk titik dan digambarkan dengan cara yang biasa bagi kita. sistem kartesius .
Mari kita jawab pertanyaan penting: berapa banyak poin yang diperlukan untuk studi kualitatif?
Lebih besar lebih baik. Set minimum yang dapat diterima terdiri dari 5-6 poin. Selain itu, dengan jumlah data yang sedikit, hasil “abnormal” tidak boleh dimasukkan dalam sampel. Jadi, misalnya, toko elit kecil dapat membantu lebih banyak daripada "rekan mereka", sehingga mendistorsi pola umum yang perlu ditemukan!
Jika cukup sederhana, kita perlu memilih fungsi , jadwal yang melewati sedekat mungkin ke titik ![]() . Fungsi seperti ini disebut mendekati
(perkiraan - perkiraan) atau fungsi teoritis
. Secara umum, di sini segera muncul "penipu" yang jelas - polinomial tingkat tinggi, yang grafiknya melewati SEMUA titik. Tetapi opsi ini rumit, dan seringkali tidak benar. (karena grafik akan "berputar" sepanjang waktu dan kurang mencerminkan tren utama).
. Fungsi seperti ini disebut mendekati
(perkiraan - perkiraan) atau fungsi teoritis
. Secara umum, di sini segera muncul "penipu" yang jelas - polinomial tingkat tinggi, yang grafiknya melewati SEMUA titik. Tetapi opsi ini rumit, dan seringkali tidak benar. (karena grafik akan "berputar" sepanjang waktu dan kurang mencerminkan tren utama).
Dengan demikian, fungsi yang diinginkan harus cukup sederhana dan pada saat yang sama mencerminkan ketergantungan secara memadai. Seperti yang Anda duga, salah satu metode untuk menemukan fungsi seperti itu disebut kuadrat terkecil. Pertama, mari kita menganalisis esensinya secara umum. Biarkan beberapa fungsi mendekati data eksperimen: 
Bagaimana cara mengevaluasi keakuratan pendekatan ini? Mari kita juga menghitung perbedaan (penyimpangan) antara nilai eksperimental dan fungsional (kami mempelajari gambarnya). Pikiran pertama yang muncul di benak adalah memperkirakan seberapa besar jumlahnya, tetapi masalahnya adalah perbedaannya bisa negatif. (Misalnya, ![]() )
dan penyimpangan sebagai akibat dari penjumlahan tersebut akan membatalkan satu sama lain. Oleh karena itu, sebagai perkiraan keakuratan aproksimasi, ia menyarankan dirinya untuk mengambil jumlah modul penyimpangan:
)
dan penyimpangan sebagai akibat dari penjumlahan tersebut akan membatalkan satu sama lain. Oleh karena itu, sebagai perkiraan keakuratan aproksimasi, ia menyarankan dirinya untuk mengambil jumlah modul penyimpangan:
![]() atau dalam bentuk terlipat: (tiba-tiba, siapa yang tidak tahu: adalah ikon penjumlahan, dan merupakan variabel tambahan-“penghitung”, yang mengambil nilai dari 1 hingga ).
atau dalam bentuk terlipat: (tiba-tiba, siapa yang tidak tahu: adalah ikon penjumlahan, dan merupakan variabel tambahan-“penghitung”, yang mengambil nilai dari 1 hingga ).
Dengan mendekati titik-titik percobaan dengan fungsi yang berbeda, kita akan memperoleh nilai yang berbeda dari , dan jelas bahwa di mana jumlah ini lebih kecil, fungsi itu lebih akurat.
Metode seperti itu ada dan disebut metode modulus terkecil. Namun, dalam praktiknya telah menjadi jauh lebih luas. metode kuadrat terkecil, di mana kemungkinan nilai negatif dihilangkan bukan oleh modulus, tetapi dengan mengkuadratkan deviasi:
![]() , setelah itu upaya diarahkan pada pemilihan fungsi sedemikian rupa sehingga jumlah deviasi kuadrat
, setelah itu upaya diarahkan pada pemilihan fungsi sedemikian rupa sehingga jumlah deviasi kuadrat ![]() adalah sekecil mungkin. Sebenarnya, itulah nama metodenya.
adalah sekecil mungkin. Sebenarnya, itulah nama metodenya.
Dan sekarang kita kembali ke poin penting lainnya: seperti disebutkan di atas, fungsi yang dipilih seharusnya cukup sederhana - tetapi ada juga banyak fungsi seperti itu: linier , hiperbolis, eksponensial, logaritma, kuadrat dll. Dan, tentu saja, di sini saya ingin segera "mengurangi bidang kegiatan". Kelas fungsi apa yang harus dipilih untuk penelitian? Teknik primitif tapi efektif:
- Cara termudah untuk menarik poin ![]() pada gambar dan menganalisis lokasi mereka. Jika mereka cenderung berada dalam garis lurus, maka Anda harus mencari persamaan garis lurus
pada gambar dan menganalisis lokasi mereka. Jika mereka cenderung berada dalam garis lurus, maka Anda harus mencari persamaan garis lurus ![]() dengan nilai optimal dan . Dengan kata lain, tugasnya adalah menemukan koefisien TERSEBUT - sehingga jumlah deviasi kuadrat adalah yang terkecil.
dengan nilai optimal dan . Dengan kata lain, tugasnya adalah menemukan koefisien TERSEBUT - sehingga jumlah deviasi kuadrat adalah yang terkecil.
Jika titik-titik itu terletak, misalnya, di sepanjang hiperbola, maka jelas bahwa fungsi linier akan memberikan aproksimasi yang buruk. Dalam hal ini, kami mencari koefisien yang paling "menguntungkan" untuk persamaan hiperbola ![]() - mereka yang memberikan jumlah kuadrat minimum
- mereka yang memberikan jumlah kuadrat minimum  .
.
Sekarang perhatikan bahwa dalam kedua kasus yang kita bicarakan fungsi dua variabel, yang argumennya adalah opsi ketergantungan yang dicari:
Dan pada intinya, kita perlu memecahkan masalah standar - untuk menemukan minimal fungsi dari dua variabel.
Ingat contoh kita: misalkan titik "toko" cenderung terletak pada garis lurus dan ada banyak alasan untuk mempercayai kehadirannya ketergantungan linier omset dari area perdagangan. Mari kita cari koefisien TERSEBUT "a" dan "menjadi" sehingga jumlah deviasi kuadrat ![]() adalah yang terkecil. Semuanya seperti biasa - pertama turunan parsial dari orde pertama. Berdasarkan aturan linearitas anda dapat membedakan tepat di bawah ikon jumlah:
adalah yang terkecil. Semuanya seperti biasa - pertama turunan parsial dari orde pertama. Berdasarkan aturan linearitas anda dapat membedakan tepat di bawah ikon jumlah: 
Jika Anda ingin menggunakan informasi ini untuk esai atau makalah, saya akan sangat berterima kasih atas tautan dalam daftar sumber, Anda tidak akan menemukan perhitungan terperinci seperti itu di mana pun: 
Mari kita membuat sistem standar: 
Kami mengurangi setiap persamaan dengan "dua" dan, sebagai tambahan, "memecah" jumlahnya: 
Catatan
: menganalisis secara independen mengapa "a" dan "menjadi" dapat diambil dari ikon jumlah. Ngomong-ngomong, secara formal ini bisa dilakukan dengan penjumlahan![]()
Mari kita tulis ulang sistem dalam bentuk "terapan": 
setelah itu algoritma untuk memecahkan masalah kita mulai ditarik:
Apakah kita tahu koordinat titik-titiknya? Kita tahu. Jumlah ![]() bisa kita temukan? Mudah. Kami membuat yang paling sederhana sistem dua persamaan linier dengan dua yang tidak diketahui("a" dan "beh"). Kami memecahkan sistem, misalnya, Metode Cramer, menghasilkan titik stasioner . Memeriksa kondisi yang cukup untuk ekstrim, kita dapat memverifikasi bahwa pada titik ini fungsinya
bisa kita temukan? Mudah. Kami membuat yang paling sederhana sistem dua persamaan linier dengan dua yang tidak diketahui("a" dan "beh"). Kami memecahkan sistem, misalnya, Metode Cramer, menghasilkan titik stasioner . Memeriksa kondisi yang cukup untuk ekstrim, kita dapat memverifikasi bahwa pada titik ini fungsinya ![]() mencapai tepat minimum. Verifikasi dikaitkan dengan perhitungan tambahan dan oleh karena itu kami akan meninggalkannya di belakang layar. (jika perlu, bingkai yang hilang dapat dilihat). Kami menarik kesimpulan akhir:
mencapai tepat minimum. Verifikasi dikaitkan dengan perhitungan tambahan dan oleh karena itu kami akan meninggalkannya di belakang layar. (jika perlu, bingkai yang hilang dapat dilihat). Kami menarik kesimpulan akhir:
Fungsi ![]() jalan terbaik (setidaknya dibandingkan dengan fungsi linier lainnya) membawa poin eksperimental lebih dekat
jalan terbaik (setidaknya dibandingkan dengan fungsi linier lainnya) membawa poin eksperimental lebih dekat ![]() . Secara kasar, grafiknya melewati sedekat mungkin ke titik-titik ini. Dalam tradisi ekonometrika fungsi aproksimasi yang dihasilkan juga disebut persamaan regresi linier berpasangan
.
. Secara kasar, grafiknya melewati sedekat mungkin ke titik-titik ini. Dalam tradisi ekonometrika fungsi aproksimasi yang dihasilkan juga disebut persamaan regresi linier berpasangan
.
Masalah yang sedang dipertimbangkan sangat penting secara praktis. Dalam situasi dengan contoh kita, persamaan ![]() memungkinkan Anda untuk memprediksi jenis omset ("yg") akan berada di toko dengan satu atau lain nilai area penjualan (satu atau arti lain dari "x"). Ya, ramalan yang dihasilkan hanya akan menjadi ramalan, tetapi dalam banyak kasus ternyata cukup akurat.
memungkinkan Anda untuk memprediksi jenis omset ("yg") akan berada di toko dengan satu atau lain nilai area penjualan (satu atau arti lain dari "x"). Ya, ramalan yang dihasilkan hanya akan menjadi ramalan, tetapi dalam banyak kasus ternyata cukup akurat.
Saya akan menganalisis hanya satu masalah dengan angka "nyata", karena tidak ada kesulitan di dalamnya - semua perhitungan berada di level kurikulum sekolah di kelas 7-8. Dalam 95 persen kasus, Anda akan diminta untuk mencari fungsi linier saja, tetapi di akhir artikel saya akan menunjukkan bahwa tidak sulit lagi menemukan persamaan untuk hiperbola optimal, eksponen, dan beberapa fungsi lainnya.
Faktanya, tetap mendistribusikan barang yang dijanjikan - sehingga Anda belajar bagaimana menyelesaikan contoh-contoh seperti itu tidak hanya secara akurat, tetapi juga dengan cepat. Kami mempelajari standar dengan cermat:
Sebuah tugas
Sebagai hasil dari mempelajari hubungan antara dua indikator, pasangan angka berikut diperoleh: 
Dengan menggunakan metode kuadrat terkecil, temukan fungsi linier yang paling mendekati fungsi empiris (berpengalaman) data. Buat gambar di mana, dalam sistem koordinat persegi panjang Cartesian, plot titik-titik eksperimental dan grafik fungsi aproksimasi ![]() . Temukan jumlah deviasi kuadrat antara nilai empiris dan teoritis. Cari tahu apakah fungsinya lebih baik (dalam hal metode kuadrat terkecil) perkiraan titik percobaan.
. Temukan jumlah deviasi kuadrat antara nilai empiris dan teoritis. Cari tahu apakah fungsinya lebih baik (dalam hal metode kuadrat terkecil) perkiraan titik percobaan.
Perhatikan bahwa nilai "x" adalah nilai alami, dan ini memiliki makna makna yang khas, yang akan saya bicarakan nanti; tetapi mereka, tentu saja, dapat berupa pecahan. Selain itu, tergantung pada konten tugas tertentu, nilai "X" dan "G" dapat sepenuhnya atau sebagian negatif. Nah, kami telah diberi tugas "tanpa wajah", dan kami memulainya larutan:
Kami menemukan koefisien fungsi optimal sebagai solusi untuk sistem: 
Untuk keperluan notasi yang lebih ringkas, variabel “penghitung” dapat dihilangkan, karena sudah jelas bahwa penjumlahan dilakukan dari 1 hingga .
Lebih mudah untuk menghitung jumlah yang diperlukan dalam bentuk tabel: 
Perhitungan dapat dilakukan pada mikrokalkulator, tetapi jauh lebih baik menggunakan Excel - lebih cepat dan tanpa kesalahan; tonton video singkatnya:
Dengan demikian, kita mendapatkan yang berikut sistem:![]()
Di sini Anda dapat mengalikan persamaan kedua dengan 3 dan kurangi suku ke-2 dari suku persamaan ke-1 dengan suku. Tapi ini keberuntungan - dalam praktiknya, sistem seringkali tidak berbakat, dan dalam kasus seperti itu menghemat Metode Cramer:
, sehingga sistem memiliki solusi yang unik.

Mari kita lakukan pemeriksaan. Saya mengerti bahwa saya tidak mau, tetapi mengapa melewatkan kesalahan di mana Anda benar-benar tidak dapat melewatkannya? Substitusikan solusi yang ditemukan ke ruas kiri setiap persamaan sistem:
Bagian yang tepat dari persamaan yang sesuai diperoleh, yang berarti bahwa sistem diselesaikan dengan benar.
Jadi, fungsi aproksimasi yang diinginkan: – dari semua fungsi linier data eksperimen paling baik didekati olehnya.
Tidak seperti lurus
ketergantungan omset toko pada luasnya, ketergantungan yang ditemukan adalah membalik
(prinsip "semakin banyak - semakin sedikit"), dan fakta ini segera terungkap oleh yang negatif koefisien sudut. Fungsi ![]() memberi tahu kita bahwa dengan peningkatan indikator tertentu sebesar 1 unit, nilai indikator dependen menurun rata-rata sebesar 0,65 unit. Seperti yang mereka katakan, semakin tinggi harga soba, semakin sedikit yang dijual.
memberi tahu kita bahwa dengan peningkatan indikator tertentu sebesar 1 unit, nilai indikator dependen menurun rata-rata sebesar 0,65 unit. Seperti yang mereka katakan, semakin tinggi harga soba, semakin sedikit yang dijual.
Untuk memplot fungsi aproksimasi, kami menemukan dua nilainya:
dan jalankan gambarnya: 
Garis yang dibangun disebut garis tren
(yaitu, garis tren linier, yaitu dalam kasus umum, tren tidak harus berupa garis lurus). Semua orang akrab dengan ungkapan "menjadi tren", dan saya pikir istilah ini tidak perlu komentar tambahan.
Hitung jumlah deviasi kuadrat ![]() antara nilai empiris dan teoritis. Secara geometris, ini adalah jumlah kuadrat dari panjang segmen "merah" (dua di antaranya sangat kecil sehingga Anda bahkan tidak dapat melihatnya).
antara nilai empiris dan teoritis. Secara geometris, ini adalah jumlah kuadrat dari panjang segmen "merah" (dua di antaranya sangat kecil sehingga Anda bahkan tidak dapat melihatnya).
Mari kita rangkum perhitungannya dalam sebuah tabel: 
Mereka dapat dilakukan lagi secara manual, untuk berjaga-jaga saya akan memberikan contoh untuk poin pertama: ![]()
tetapi jauh lebih efisien untuk melakukan cara yang sudah diketahui:
Mari kita ulangi: apa arti dari hasil Dari semua fungsi linier fungsi ![]() eksponennya adalah yang terkecil, yaitu aproksimasi terbaik dalam keluarganya. Dan di sini, omong-omong, pertanyaan terakhir dari masalah ini bukanlah kebetulan: bagaimana jika fungsi eksponensial yang diusulkan
eksponennya adalah yang terkecil, yaitu aproksimasi terbaik dalam keluarganya. Dan di sini, omong-omong, pertanyaan terakhir dari masalah ini bukanlah kebetulan: bagaimana jika fungsi eksponensial yang diusulkan ![]() akan lebih baik untuk mendekati titik percobaan?
akan lebih baik untuk mendekati titik percobaan?
Mari kita temukan jumlah deviasi kuadrat yang sesuai - untuk membedakannya, saya akan menunjuknya dengan huruf "epsilon". Tekniknya persis sama: 
Dan lagi untuk setiap perhitungan api untuk poin pertama: 
Di Excel, kami menggunakan fungsi standar EXP (Sintaks dapat ditemukan di Bantuan Excel).
Kesimpulan: , jadi fungsi eksponensial mendekati titik eksperimen lebih buruk daripada garis lurus ![]() .
.
Tetapi perlu dicatat di sini bahwa "lebih buruk" adalah belum berarti, apa yang salah. Sekarang saya membuat grafik fungsi eksponensial ini - dan juga mendekati titik ![]() - sedemikian rupa sehingga tanpa studi analitis sulit untuk mengatakan fungsi mana yang lebih akurat.
- sedemikian rupa sehingga tanpa studi analitis sulit untuk mengatakan fungsi mana yang lebih akurat.
Ini melengkapi solusinya, dan saya kembali ke pertanyaan tentang nilai-nilai alami dari argumen tersebut. Dalam berbagai penelitian, sebagai aturan, ekonomi atau sosiologis, bulan, tahun, atau interval waktu lain yang sama diberi nomor dengan "X" alami. Pertimbangkan, misalnya, masalah seperti itu.
Contoh.
Data eksperimen tentang nilai-nilai variabel X dan pada diberikan dalam tabel. 
Sebagai hasil dari penyelarasannya, fungsi ![]()
Menggunakan metode kuadrat terkecil, perkiraan data ini dengan ketergantungan linier y=ax+b(temukan parameter sebuah dan b). Cari tahu mana dari dua garis yang lebih baik (dalam arti metode kuadrat terkecil) menyelaraskan data eksperimen. Membuat gambar.
Inti dari metode kuadrat terkecil (LSM).
Masalahnya adalah untuk menemukan koefisien ketergantungan linier yang fungsi dari dua variabel sebuah dan b ![]() mengambil nilai terkecil. Artinya, mengingat data sebuah dan b jumlah deviasi kuadrat dari data eksperimen dari garis lurus yang ditemukan akan menjadi yang terkecil. Ini adalah inti dari metode kuadrat terkecil.
mengambil nilai terkecil. Artinya, mengingat data sebuah dan b jumlah deviasi kuadrat dari data eksperimen dari garis lurus yang ditemukan akan menjadi yang terkecil. Ini adalah inti dari metode kuadrat terkecil.
Dengan demikian, solusi dari contoh direduksi menjadi menemukan ekstrem dari fungsi dua variabel.
Turunan rumus untuk mencari koefisien.
Sistem dua persamaan dengan dua yang tidak diketahui disusun dan diselesaikan. Menemukan turunan parsial dari suatu fungsi sehubungan dengan variabel sebuah dan b, kita menyamakan turunan ini dengan nol. 
Kami memecahkan sistem persamaan yang dihasilkan dengan metode apa pun (misalnya metode substitusi atau ) dan dapatkan rumus untuk mencari koefisien menggunakan metode kuadrat terkecil (LSM). 
Dengan data sebuah dan b fungsi ![]() mengambil nilai terkecil. Bukti dari fakta ini diberikan.
mengambil nilai terkecil. Bukti dari fakta ini diberikan.
Itulah seluruh metode kuadrat terkecil. Rumus untuk mencari parameter sebuah berisi jumlah , , , dan parameter n- jumlah data eksperimen. Nilai dari jumlah ini direkomendasikan untuk dihitung secara terpisah. Koefisien b ditemukan setelah perhitungan sebuah.
Saatnya untuk mengingat contoh aslinya.
Larutan.
Dalam contoh kita n=5. Kami mengisi tabel untuk kenyamanan menghitung jumlah yang termasuk dalam rumus koefisien yang diperlukan. 
Nilai pada baris keempat tabel diperoleh dengan mengalikan nilai baris ke-2 dengan nilai baris ke-3 untuk setiap angka saya.
Nilai pada baris kelima tabel diperoleh dengan mengkuadratkan nilai baris ke-2 untuk setiap angka saya.
Nilai kolom terakhir dari tabel adalah jumlah nilai di seluruh baris.
Kami menggunakan rumus metode kuadrat terkecil untuk menemukan koefisien sebuah dan b. Kami menggantinya dengan nilai yang sesuai dari kolom terakhir tabel: 
Akibatnya, y=0.165x+2.184 adalah garis lurus aproksimasi yang diinginkan.
Masih mencari tahu yang mana dari garis y=0.165x+2.184 atau ![]() lebih baik mendekati data asli, yaitu membuat perkiraan menggunakan metode kuadrat terkecil.
lebih baik mendekati data asli, yaitu membuat perkiraan menggunakan metode kuadrat terkecil.
Estimasi kesalahan metode kuadrat terkecil.
Untuk melakukan ini, Anda perlu menghitung jumlah deviasi kuadrat dari data asli dari garis-garis ini ![]() dan
dan ![]() , nilai yang lebih kecil sesuai dengan garis yang lebih mendekati data asli dalam hal metode kuadrat terkecil.
, nilai yang lebih kecil sesuai dengan garis yang lebih mendekati data asli dalam hal metode kuadrat terkecil. 
Karena , maka garis y=0.165x+2.184 mendekati data asli dengan lebih baik.
Ilustrasi grafis dari metode kuadrat terkecil (LSM).
Semuanya tampak hebat di tangga lagu. Garis merah adalah garis yang ditemukan y=0.165x+2.184, garis biru adalah ![]() , titik-titik merah muda adalah data asli.
, titik-titik merah muda adalah data asli.

Untuk apa, untuk apa semua perkiraan ini?
Saya pribadi menggunakan untuk memecahkan masalah pemulusan data, masalah interpolasi dan ekstrapolasi (dalam contoh asli, Anda dapat diminta untuk menemukan nilai dari nilai yang diamati kamu pada x=3 atau kapan x=6 menurut metode MNC). Tetapi kita akan membicarakan lebih lanjut tentang ini nanti di bagian lain situs ini.
Bukti.
Sehingga ketika ditemukan sebuah dan b fungsi mengambil nilai terkecil, perlu bahwa pada titik ini matriks bentuk kuadrat dari diferensial orde kedua untuk fungsi ![]() pasti positif. Mari kita tunjukkan.
pasti positif. Mari kita tunjukkan.
Diferensial orde kedua memiliki bentuk: 
Itu adalah
Oleh karena itu, matriks bentuk kuadrat memiliki bentuk 
dan nilai elemen tidak bergantung pada sebuah dan b.
Mari kita tunjukkan bahwa matriks tersebut pasti positif. Ini mensyaratkan bahwa sudut minor harus positif.
Minor sudut dari orde pertama  . Ketimpangannya sangat ketat, karena titik-titiknya tidak bertepatan. Ini akan tersirat dalam apa yang berikut.
. Ketimpangannya sangat ketat, karena titik-titiknya tidak bertepatan. Ini akan tersirat dalam apa yang berikut.
Minor sudut dari orde kedua 
Ayo buktikan  dengan metode induksi matematika.
dengan metode induksi matematika.

Kesimpulan: nilai yang ditemukan sebuah dan b sesuai dengan nilai terkecil dari fungsi ![]() , oleh karena itu, adalah parameter yang diinginkan untuk metode kuadrat terkecil.
, oleh karena itu, adalah parameter yang diinginkan untuk metode kuadrat terkecil.
Metode kuadrat terkecil
Dalam pelajaran terakhir dari topik ini, kita akan berkenalan dengan aplikasi paling terkenal FNP, yang menemukan aplikasi terluas di berbagai bidang ilmu pengetahuan dan praktek. Bisa fisika, kimia, biologi, ekonomi, sosiologi, psikologi dan lain sebagainya. Dengan kehendak takdir, saya sering harus berurusan dengan ekonomi, dan karena itu hari ini saya akan mengaturkan Anda tiket ke negara yang menakjubkan bernama ekonometrika=) … Bagaimana Anda tidak menginginkannya?! Sangat bagus di sana - Anda hanya perlu memutuskan! …Tapi yang mungkin Anda inginkan adalah belajar bagaimana memecahkan masalah kuadrat terkecil. Dan terutama pembaca yang rajin akan belajar menyelesaikannya tidak hanya secara akurat, tetapi juga SANGAT CEPAT ;-) Tapi pertama-tama pernyataan umum dari masalah+ contoh terkait:
Biarkan indikator dipelajari di beberapa bidang studi yang memiliki ekspresi kuantitatif. Pada saat yang sama, ada banyak alasan untuk percaya bahwa indikator bergantung pada indikator. Asumsi ini dapat berupa hipotesis ilmiah dan berdasarkan akal sehat dasar. Namun, mari kita kesampingkan sains, dan jelajahi area yang lebih menggugah selera - yaitu, toko kelontong. Dilambangkan dengan:
– ruang ritel toko kelontong, sq.m.,
- omset tahunan toko kelontong, juta rubel.
Cukup jelas bahwa semakin besar area toko, semakin besar omsetnya dalam banyak kasus.
Misalkan setelah melakukan pengamatan / eksperimen / perhitungan / menari dengan rebana, kami memiliki data numerik yang kami miliki: 
Dengan toko kelontong, saya pikir semuanya jelas: - ini adalah area toko pertama, - omset tahunannya, - area toko ke-2, - omset tahunannya, dll. Ngomong-ngomong, sama sekali tidak perlu memiliki akses ke materi rahasia - penilaian omset yang cukup akurat dapat diperoleh dengan menggunakan statistik matematika. Namun, jangan terganggu, kursus spionase komersial sudah dibayar =)
Data tabular juga dapat ditulis dalam bentuk titik dan digambarkan dengan cara yang biasa bagi kita. sistem kartesius .
Mari kita jawab pertanyaan penting: berapa banyak poin yang diperlukan untuk studi kualitatif?
Lebih besar lebih baik. Set minimum yang dapat diterima terdiri dari 5-6 poin. Selain itu, dengan jumlah data yang sedikit, hasil “abnormal” tidak boleh dimasukkan dalam sampel. Jadi, misalnya, toko elit kecil dapat membantu lebih banyak daripada "rekan mereka", sehingga mendistorsi pola umum yang perlu ditemukan!
Jika cukup sederhana, kita perlu memilih fungsi , jadwal yang melewati sedekat mungkin ke titik ![]() . Fungsi seperti ini disebut mendekati
(perkiraan - perkiraan) atau fungsi teoritis
. Secara umum, di sini segera muncul "penipu" yang jelas - polinomial tingkat tinggi, yang grafiknya melewati SEMUA titik. Tetapi opsi ini rumit, dan seringkali tidak benar. (karena grafik akan "berputar" sepanjang waktu dan kurang mencerminkan tren utama).
. Fungsi seperti ini disebut mendekati
(perkiraan - perkiraan) atau fungsi teoritis
. Secara umum, di sini segera muncul "penipu" yang jelas - polinomial tingkat tinggi, yang grafiknya melewati SEMUA titik. Tetapi opsi ini rumit, dan seringkali tidak benar. (karena grafik akan "berputar" sepanjang waktu dan kurang mencerminkan tren utama).
Dengan demikian, fungsi yang diinginkan harus cukup sederhana dan pada saat yang sama mencerminkan ketergantungan secara memadai. Seperti yang Anda duga, salah satu metode untuk menemukan fungsi seperti itu disebut kuadrat terkecil. Pertama, mari kita menganalisis esensinya secara umum. Biarkan beberapa fungsi mendekati data eksperimen: 
Bagaimana cara mengevaluasi keakuratan pendekatan ini? Mari kita juga menghitung perbedaan (penyimpangan) antara nilai eksperimental dan fungsional (kami mempelajari gambarnya). Pikiran pertama yang muncul di benak adalah memperkirakan seberapa besar jumlahnya, tetapi masalahnya adalah perbedaannya bisa negatif. (Misalnya, ![]() )
dan penyimpangan sebagai akibat dari penjumlahan tersebut akan membatalkan satu sama lain. Oleh karena itu, sebagai perkiraan keakuratan aproksimasi, ia menyarankan dirinya untuk mengambil jumlah modul penyimpangan:
)
dan penyimpangan sebagai akibat dari penjumlahan tersebut akan membatalkan satu sama lain. Oleh karena itu, sebagai perkiraan keakuratan aproksimasi, ia menyarankan dirinya untuk mengambil jumlah modul penyimpangan:
![]() atau dalam bentuk terlipat: (bagi yang belum tahu:
adalah ikon penjumlahan, dan
- variabel tambahan - "penghitung", yang mengambil nilai dari 1 hingga
)
.
atau dalam bentuk terlipat: (bagi yang belum tahu:
adalah ikon penjumlahan, dan
- variabel tambahan - "penghitung", yang mengambil nilai dari 1 hingga
)
.
Mendekati titik eksperimental dengan fungsi yang berbeda, kita akan mendapatkan nilai yang berbeda, dan jelas di mana jumlah ini lebih kecil - fungsi itu lebih akurat.
Metode seperti itu ada dan disebut metode modulus terkecil. Namun, dalam praktiknya telah menjadi jauh lebih luas. metode kuadrat terkecil, di mana kemungkinan nilai negatif dihilangkan bukan oleh modulus, tetapi dengan mengkuadratkan deviasi:
![]() , setelah itu upaya diarahkan pada pemilihan fungsi sedemikian rupa sehingga jumlah deviasi kuadrat
, setelah itu upaya diarahkan pada pemilihan fungsi sedemikian rupa sehingga jumlah deviasi kuadrat ![]() adalah sekecil mungkin. Sebenarnya, itulah nama metodenya.
adalah sekecil mungkin. Sebenarnya, itulah nama metodenya.
Dan sekarang kita kembali ke poin penting lainnya: seperti disebutkan di atas, fungsi yang dipilih seharusnya cukup sederhana - tetapi ada juga banyak fungsi seperti itu: linier , hiperbolis , eksponensial , logaritma , kuadrat dll. Dan, tentu saja, di sini saya ingin segera "mengurangi bidang kegiatan". Kelas fungsi apa yang harus dipilih untuk penelitian? Teknik primitif tapi efektif:
- Cara termudah untuk menarik poin ![]() pada gambar dan menganalisis lokasi mereka. Jika mereka cenderung berada dalam garis lurus, maka Anda harus mencari persamaan garis lurus
pada gambar dan menganalisis lokasi mereka. Jika mereka cenderung berada dalam garis lurus, maka Anda harus mencari persamaan garis lurus ![]() dengan nilai optimal dan . Dengan kata lain, tugasnya adalah menemukan koefisien TERSEBUT - sehingga jumlah deviasi kuadrat adalah yang terkecil.
dengan nilai optimal dan . Dengan kata lain, tugasnya adalah menemukan koefisien TERSEBUT - sehingga jumlah deviasi kuadrat adalah yang terkecil.
Jika titik-titik itu terletak, misalnya, di sepanjang hiperbola, maka jelas bahwa fungsi linier akan memberikan aproksimasi yang buruk. Dalam hal ini, kami mencari koefisien yang paling "menguntungkan" untuk persamaan hiperbola ![]() - mereka yang memberikan jumlah kuadrat minimum
- mereka yang memberikan jumlah kuadrat minimum  .
.
Sekarang perhatikan bahwa dalam kedua kasus yang kita bicarakan fungsi dua variabel, yang argumennya adalah opsi ketergantungan yang dicari:
Dan pada intinya, kita perlu memecahkan masalah standar - untuk menemukan minimal fungsi dari dua variabel.
Ingat contoh kita: misalkan titik "toko" cenderung terletak pada garis lurus dan ada banyak alasan untuk mempercayai kehadirannya ketergantungan linier omset dari area perdagangan. Mari kita cari koefisien TERSEBUT "a" dan "menjadi" sehingga jumlah deviasi kuadrat ![]() adalah yang terkecil. Semuanya seperti biasa - pertama turunan parsial dari orde pertama. Berdasarkan aturan linearitas anda dapat membedakan tepat di bawah ikon jumlah:
adalah yang terkecil. Semuanya seperti biasa - pertama turunan parsial dari orde pertama. Berdasarkan aturan linearitas anda dapat membedakan tepat di bawah ikon jumlah: 
Jika Anda ingin menggunakan informasi ini untuk esai atau makalah, saya akan sangat berterima kasih atas tautan dalam daftar sumber, Anda tidak akan menemukan perhitungan terperinci seperti itu di mana pun: 
Mari kita membuat sistem standar: 
Kami mengurangi setiap persamaan dengan "dua" dan, sebagai tambahan, "memecah" jumlahnya: 
Catatan
: menganalisis secara independen mengapa "a" dan "menjadi" dapat diambil dari ikon jumlah. Ngomong-ngomong, secara formal ini bisa dilakukan dengan penjumlahan ![]()
Mari kita tulis ulang sistem dalam bentuk "terapan": 
setelah itu algoritma untuk memecahkan masalah kita mulai ditarik:
Apakah kita tahu koordinat titik-titiknya? Kita tahu. Jumlah ![]() bisa kita temukan? Mudah. Kami membuat yang paling sederhana sistem dua persamaan linier dengan dua yang tidak diketahui("a" dan "beh"). Kami memecahkan sistem, misalnya, Metode Cramer, menghasilkan titik stasioner . Memeriksa kondisi yang cukup untuk ekstrim, kita dapat memverifikasi bahwa pada titik ini fungsinya
bisa kita temukan? Mudah. Kami membuat yang paling sederhana sistem dua persamaan linier dengan dua yang tidak diketahui("a" dan "beh"). Kami memecahkan sistem, misalnya, Metode Cramer, menghasilkan titik stasioner . Memeriksa kondisi yang cukup untuk ekstrim, kita dapat memverifikasi bahwa pada titik ini fungsinya ![]() mencapai tepat minimum. Verifikasi dikaitkan dengan perhitungan tambahan dan oleh karena itu kami akan meninggalkannya di belakang layar. (jika perlu, bingkai yang hilang dapat dilihatdi sini
)
. Kami menarik kesimpulan akhir:
mencapai tepat minimum. Verifikasi dikaitkan dengan perhitungan tambahan dan oleh karena itu kami akan meninggalkannya di belakang layar. (jika perlu, bingkai yang hilang dapat dilihatdi sini
)
. Kami menarik kesimpulan akhir:
Fungsi ![]() jalan terbaik (setidaknya dibandingkan dengan fungsi linier lainnya) membawa poin eksperimental lebih dekat
jalan terbaik (setidaknya dibandingkan dengan fungsi linier lainnya) membawa poin eksperimental lebih dekat ![]() . Secara kasar, grafiknya melewati sedekat mungkin ke titik-titik ini. Dalam tradisi ekonometrika fungsi aproksimasi yang dihasilkan juga disebut persamaan regresi linier berpasangan
.
. Secara kasar, grafiknya melewati sedekat mungkin ke titik-titik ini. Dalam tradisi ekonometrika fungsi aproksimasi yang dihasilkan juga disebut persamaan regresi linier berpasangan
.
Masalah yang sedang dipertimbangkan sangat penting secara praktis. Dalam situasi dengan contoh kita, persamaan ![]() memungkinkan Anda untuk memprediksi jenis omset ("yg") akan berada di toko dengan satu atau lain nilai area penjualan (satu atau arti lain dari "x"). Ya, ramalan yang dihasilkan hanya akan menjadi ramalan, tetapi dalam banyak kasus ternyata cukup akurat.
memungkinkan Anda untuk memprediksi jenis omset ("yg") akan berada di toko dengan satu atau lain nilai area penjualan (satu atau arti lain dari "x"). Ya, ramalan yang dihasilkan hanya akan menjadi ramalan, tetapi dalam banyak kasus ternyata cukup akurat.
Saya akan menganalisis hanya satu masalah dengan angka "nyata", karena tidak ada kesulitan di dalamnya - semua perhitungan berada di level kurikulum sekolah di kelas 7-8. Dalam 95 persen kasus, Anda akan diminta untuk mencari fungsi linier saja, tetapi di akhir artikel saya akan menunjukkan bahwa tidak sulit lagi menemukan persamaan untuk hiperbola optimal, eksponen, dan beberapa fungsi lainnya.
Faktanya, tetap mendistribusikan barang yang dijanjikan - sehingga Anda belajar bagaimana menyelesaikan contoh-contoh seperti itu tidak hanya secara akurat, tetapi juga dengan cepat. Kami mempelajari standar dengan cermat:
Sebuah tugas
Sebagai hasil dari mempelajari hubungan antara dua indikator, pasangan angka berikut diperoleh: 
Dengan menggunakan metode kuadrat terkecil, temukan fungsi linier yang paling mendekati fungsi empiris (berpengalaman) data. Buat gambar di mana, dalam sistem koordinat persegi panjang Cartesian, plot titik-titik eksperimental dan grafik fungsi aproksimasi ![]() . Temukan jumlah deviasi kuadrat antara nilai empiris dan teoritis. Cari tahu apakah fungsinya lebih baik (dalam hal metode kuadrat terkecil) perkiraan titik percobaan.
. Temukan jumlah deviasi kuadrat antara nilai empiris dan teoritis. Cari tahu apakah fungsinya lebih baik (dalam hal metode kuadrat terkecil) perkiraan titik percobaan.
Perhatikan bahwa nilai "x" adalah nilai alami, dan ini memiliki makna makna yang khas, yang akan saya bicarakan nanti; tetapi mereka, tentu saja, dapat berupa pecahan. Selain itu, tergantung pada konten tugas tertentu, nilai "X" dan "G" dapat sepenuhnya atau sebagian negatif. Nah, kami telah diberi tugas "tanpa wajah", dan kami memulainya larutan:
Kami menemukan koefisien fungsi optimal sebagai solusi untuk sistem: 
Untuk keperluan notasi yang lebih ringkas, variabel “penghitung” dapat dihilangkan, karena sudah jelas bahwa penjumlahan dilakukan dari 1 hingga .
Lebih mudah untuk menghitung jumlah yang diperlukan dalam bentuk tabel: 
Perhitungan dapat dilakukan pada mikrokalkulator, tetapi jauh lebih baik menggunakan Excel - lebih cepat dan tanpa kesalahan; tonton video singkatnya:
Dengan demikian, kita mendapatkan yang berikut sistem:![]()
Di sini Anda dapat mengalikan persamaan kedua dengan 3 dan kurangi suku ke-2 dari suku persamaan ke-1 dengan suku. Tapi ini keberuntungan - dalam praktiknya, sistem seringkali tidak berbakat, dan dalam kasus seperti itu menghemat Metode Cramer:
, sehingga sistem memiliki solusi yang unik.

Mari kita lakukan pemeriksaan. Saya mengerti bahwa saya tidak mau, tetapi mengapa melewatkan kesalahan di mana Anda benar-benar tidak dapat melewatkannya? Substitusikan solusi yang ditemukan ke ruas kiri setiap persamaan sistem:
Bagian yang tepat dari persamaan yang sesuai diperoleh, yang berarti bahwa sistem diselesaikan dengan benar.
Jadi, fungsi aproksimasi yang diinginkan: – dari semua fungsi linier data eksperimen paling baik didekati olehnya.
Tidak seperti lurus
ketergantungan omset toko pada luasnya, ketergantungan yang ditemukan adalah membalik
(prinsip "semakin banyak - semakin sedikit"), dan fakta ini segera terungkap oleh yang negatif koefisien sudut. Fungsi ![]() memberi tahu kita bahwa dengan peningkatan indikator tertentu sebesar 1 unit, nilai indikator dependen menurun rata-rata sebesar 0,65 unit. Seperti yang mereka katakan, semakin tinggi harga soba, semakin sedikit yang dijual.
memberi tahu kita bahwa dengan peningkatan indikator tertentu sebesar 1 unit, nilai indikator dependen menurun rata-rata sebesar 0,65 unit. Seperti yang mereka katakan, semakin tinggi harga soba, semakin sedikit yang dijual.
Untuk memplot fungsi aproksimasi, kami menemukan dua nilainya:
dan jalankan gambarnya: 
Garis yang dibangun disebut garis tren
(yaitu, garis tren linier, yaitu dalam kasus umum, tren tidak harus berupa garis lurus). Semua orang akrab dengan ungkapan "menjadi tren", dan saya pikir istilah ini tidak perlu komentar tambahan.
Hitung jumlah deviasi kuadrat ![]() antara nilai empiris dan teoritis. Secara geometris, ini adalah jumlah kuadrat dari panjang segmen "merah" (dua di antaranya sangat kecil sehingga Anda bahkan tidak dapat melihatnya).
antara nilai empiris dan teoritis. Secara geometris, ini adalah jumlah kuadrat dari panjang segmen "merah" (dua di antaranya sangat kecil sehingga Anda bahkan tidak dapat melihatnya).
Mari kita rangkum perhitungannya dalam sebuah tabel: 
Mereka dapat dilakukan lagi secara manual, untuk berjaga-jaga saya akan memberikan contoh untuk poin pertama: ![]()
tetapi jauh lebih efisien untuk melakukan cara yang sudah diketahui:
Mari kita ulangi: apa arti dari hasil Dari semua fungsi linier fungsi ![]() eksponennya adalah yang terkecil, yaitu aproksimasi terbaik dalam keluarganya. Dan di sini, omong-omong, pertanyaan terakhir dari masalah ini bukanlah kebetulan: bagaimana jika fungsi eksponensial yang diusulkan
eksponennya adalah yang terkecil, yaitu aproksimasi terbaik dalam keluarganya. Dan di sini, omong-omong, pertanyaan terakhir dari masalah ini bukanlah kebetulan: bagaimana jika fungsi eksponensial yang diusulkan ![]() akan lebih baik untuk mendekati titik percobaan?
akan lebih baik untuk mendekati titik percobaan?
Mari kita temukan jumlah deviasi kuadrat yang sesuai - untuk membedakannya, saya akan menunjuknya dengan huruf "epsilon". Tekniknya persis sama: 
Dan lagi untuk setiap perhitungan api untuk poin pertama: 
Di Excel, kami menggunakan fungsi standar EXP (Sintaks dapat ditemukan di Bantuan Excel).
Kesimpulan: , jadi fungsi eksponensial mendekati titik eksperimen lebih buruk daripada garis lurus ![]() .
.
Tetapi perlu dicatat di sini bahwa "lebih buruk" adalah belum berarti, apa yang salah. Sekarang saya membuat grafik fungsi eksponensial ini - dan juga mendekati titik ![]() - sedemikian rupa sehingga tanpa studi analitis sulit untuk mengatakan fungsi mana yang lebih akurat.
- sedemikian rupa sehingga tanpa studi analitis sulit untuk mengatakan fungsi mana yang lebih akurat.
Ini melengkapi solusinya, dan saya kembali ke pertanyaan tentang nilai-nilai alami dari argumen tersebut. Dalam berbagai penelitian, sebagai aturan, ekonomi atau sosiologis, bulan, tahun, atau interval waktu lain yang sama diberi nomor dengan "X" alami. Pertimbangkan, misalnya, masalah berikut:
Kami memiliki data berikut tentang omset ritel toko untuk paruh pertama tahun ini:
Menggunakan perataan analitik garis lurus, temukan volume penjualan untuk bulan Juli.
Ya, tidak masalah: kami memberi nomor bulan 1, 2, 3, 4, 5, 6 dan menggunakan algoritma yang biasa, sebagai hasilnya kami mendapatkan persamaan - satu-satunya hal ketika datang ke waktu biasanya huruf "te " (walaupun tidak kritis). Persamaan yang dihasilkan menunjukkan bahwa pada semester pertama tahun ini, omzet meningkat rata-rata sebesar Rp 27,74. per bulan. Dapatkan perkiraan untuk bulan Juli (bulan #7): e.u.
Dan tugas serupa - kegelapan itu gelap. Yang mau bisa menggunakan layanan tambahan yaitu my kalkulator excel (versi demo), yang memecahkan masalah hampir seketika! Versi kerja dari program ini tersedia sebagai gantinya atau untuk pembayaran simbolis.
Di akhir pelajaran, informasi singkat tentang menemukan dependensi dari beberapa jenis lain. Sebenarnya, tidak ada yang istimewa untuk diceritakan, karena pendekatan fundamental dan algoritma solusi tetap sama.
Mari kita asumsikan bahwa lokasi titik percobaan menyerupai hiperbola. Kemudian, untuk menemukan koefisien hiperbola terbaik, Anda perlu menemukan fungsi minimum - mereka yang ingin dapat melakukan perhitungan terperinci dan datang ke sistem serupa: 
Dari sudut pandang teknis formal, diperoleh dari sistem "linier"  (mari kita tandai dengan tanda bintang) mengganti "x" dengan . Nah, jumlahnya
(mari kita tandai dengan tanda bintang) mengganti "x" dengan . Nah, jumlahnya ![]() hitung, setelah itu ke koefisien optimal "a" dan "menjadi" di tangan.
hitung, setelah itu ke koefisien optimal "a" dan "menjadi" di tangan.
Jika ada alasan untuk percaya bahwa poin ![]() disusun sepanjang kurva logaritmik, kemudian untuk mencari nilai optimal dan menemukan fungsi minimum
disusun sepanjang kurva logaritmik, kemudian untuk mencari nilai optimal dan menemukan fungsi minimum ![]() . Secara formal, dalam sistem (*) harus diganti dengan:
. Secara formal, dalam sistem (*) harus diganti dengan: 
Saat menghitung di Excel, gunakan fungsi LN. Saya akui bahwa tidak akan sulit bagi saya untuk membuat kalkulator untuk setiap kasus yang sedang dipertimbangkan, tetapi akan lebih baik jika Anda "memprogram" perhitungannya sendiri. Video tutorial untuk membantu.
Dengan ketergantungan eksponensial, situasinya sedikit lebih rumit. Untuk mengurangi masalah ke kasus linier, kami mengambil logaritma dari fungsi dan menggunakan sifat-sifat logaritma:
Sekarang, membandingkan fungsi yang diperoleh dengan fungsi linier , kita sampai pada kesimpulan bahwa dalam sistem (*) harus diganti oleh , dan - oleh . Untuk kenyamanan, kami menunjukkan: 
Harap dicatat bahwa sistem diselesaikan sehubungan dengan dan , dan oleh karena itu, setelah menemukan akarnya, Anda tidak boleh lupa untuk menemukan koefisien itu sendiri.
Untuk memperkirakan titik eksperimental ![]() parabola optimal
parabola optimal ![]() , harus ditemukan minimal fungsi dari tiga variabel
, harus ditemukan minimal fungsi dari tiga variabel ![]() . Setelah melakukan tindakan standar, kami mendapatkan "bekerja" berikut sistem:
. Setelah melakukan tindakan standar, kami mendapatkan "bekerja" berikut sistem:
Ya tentu saja jumlahnya lebih banyak di sini, tetapi tidak ada kesulitan sama sekali saat menggunakan aplikasi favorit Anda. Dan akhirnya, saya akan memberi tahu Anda cara cepat memeriksa menggunakan Excel dan membangun garis tren yang diinginkan: buat bagan sebar, pilih salah satu titik dengan mouse ![]() dan klik kanan pilih opsi "Tambahkan garis tren". Selanjutnya, pilih jenis grafik dan pada tab "Pilihan" aktifkan opsi "Tampilkan persamaan pada grafik". Oke
dan klik kanan pilih opsi "Tambahkan garis tren". Selanjutnya, pilih jenis grafik dan pada tab "Pilihan" aktifkan opsi "Tampilkan persamaan pada grafik". Oke
Seperti biasa, saya ingin mengakhiri artikel dengan frasa yang indah, dan saya hampir mengetik "Jadilah tren!". Namun lama kelamaan dia berubah pikiran. Dan bukan karena formulanya. Saya tidak tahu bagaimana orang, tetapi saya tidak ingin mengikuti tren Amerika dan terutama Eropa yang dipromosikan sama sekali =) Oleh karena itu, saya berharap Anda masing-masing untuk tetap pada jalur Anda sendiri!
http://www.grandars.ru/student/vysshaya-matematika/metod-naimenshih-kvadratov.html
Metode kuadrat terkecil adalah salah satu yang paling umum dan paling berkembang karena kesederhanaan dan efisiensi metode untuk memperkirakan parameter model ekonometrik linier. Pada saat yang sama, kehati-hatian tertentu harus diperhatikan saat menggunakannya, karena model yang dibuat dengan menggunakannya mungkin tidak memenuhi sejumlah persyaratan untuk kualitas parameternya dan, sebagai akibatnya, tidak mencerminkan pola pengembangan proses dengan "baik".
Mari kita pertimbangkan prosedur untuk memperkirakan parameter model ekonometrik linier menggunakan metode kuadrat terkecil secara lebih rinci. Model seperti itu dalam bentuk umum dapat diwakili oleh persamaan (1.2):
y t = a 0 + a 1 x 1t +...+ a n x nt + t .
Data awal saat menaksir parameter a 0 , a 1 ,..., a n adalah vektor dari nilai variabel dependen kamu= (y 1 , y 2 , ... , y T)" dan matriks nilai variabel bebas

di mana kolom pertama, yang terdiri dari satu, sesuai dengan koefisien model .
Metode kuadrat terkecil mendapatkan namanya berdasarkan prinsip dasar bahwa estimasi parameter yang diperoleh atas dasar itu harus memenuhi: jumlah kuadrat dari kesalahan model harus minimal.
Contoh penyelesaian masalah dengan metode kuadrat terkecil
Contoh 2.1. Perusahaan perdagangan memiliki jaringan yang terdiri dari 12 toko, informasi tentang kegiatannya disajikan pada Tabel. 2.1.
Manajemen perusahaan ingin mengetahui bagaimana ukuran omset tahunan tergantung pada ruang ritel toko.
Tabel 2.1
| Nomor toko | Omset tahunan, juta rubel | Area perdagangan, ribu m 2 |
| 19,76 | 0,24 | |
| 38,09 | 0,31 | |
| 40,95 | 0,55 | |
| 41,08 | 0,48 | |
| 56,29 | 0,78 | |
| 68,51 | 0,98 | |
| 75,01 | 0,94 | |
| 89,05 | 1,21 | |
| 91,13 | 1,29 | |
| 91,26 | 1,12 | |
| 99,84 | 1,29 | |
| 108,55 | 1,49 |
Solusi kuadrat terkecil. Mari kita tentukan - omset tahunan toko -th, juta rubel; - luas jual toko ke th, ribu m 2.

Gambar 2.1. Scatterplot untuk Contoh 2.1
Untuk menentukan bentuk hubungan fungsional antar variabel dan membangun scatterplot (Gbr. 2.1).
Berdasarkan diagram pencar, kita dapat menyimpulkan bahwa omset tahunan secara positif bergantung pada area penjualan (yaitu, y akan meningkat dengan pertumbuhan ). Bentuk koneksi fungsional yang paling tepat adalah linier.
Informasi untuk perhitungan lebih lanjut disajikan pada Tabel. 2.2. Dengan menggunakan metode kuadrat terkecil, kami memperkirakan parameter model ekonometrik satu faktor linier

Tabel 2.2
| t | y t | x 1t | y t 2 | x1t2 | x 1t y t |
| 19,76 | 0,24 | 390,4576 | 0,0576 | 4,7424 | |
| 38,09 | 0,31 | 1450,8481 | 0,0961 | 11,8079 | |
| 40,95 | 0,55 | 1676,9025 | 0,3025 | 22,5225 | |
| 41,08 | 0,48 | 1687,5664 | 0,2304 | 19,7184 | |
| 56,29 | 0,78 | 3168,5641 | 0,6084 | 43,9062 | |
| 68,51 | 0,98 | 4693,6201 | 0,9604 | 67,1398 | |
| 75,01 | 0,94 | 5626,5001 | 0,8836 | 70,5094 | |
| 89,05 | 1,21 | 7929,9025 | 1,4641 | 107,7505 | |
| 91,13 | 1,29 | 8304,6769 | 1,6641 | 117,5577 | |
| 91,26 | 1,12 | 8328,3876 | 1,2544 | 102,2112 | |
| 99,84 | 1,29 | 9968,0256 | 1,6641 | 128,7936 | |
| 108,55 | 1,49 | 11783,1025 | 2,2201 | 161,7395 | |
| S | 819,52 | 10,68 | 65008,554 | 11,4058 | 858,3991 |
| Rata-rata | 68,29 | 0,89 |
Lewat sini,
Oleh karena itu, dengan peningkatan area perdagangan sebesar 1 ribu m 2, hal-hal lain dianggap sama, omset tahunan rata-rata meningkat sebesar 67,8871 juta rubel.
Contoh 2.2. Manajemen perusahaan memperhatikan bahwa omset tahunan tidak hanya bergantung pada area penjualan toko (lihat contoh 2.1), tetapi juga pada jumlah rata-rata pengunjung. Informasi yang relevan disajikan dalam tabel. 2.3.
Tabel 2.3
Larutan. Menunjukkan - jumlah rata-rata pengunjung ke toko per hari, ribu orang.
Untuk menentukan bentuk hubungan fungsional antar variabel dan membangun scatterplot (Gbr. 2.2).
Berdasarkan diagram pencar, kita dapat menyimpulkan bahwa omset tahunan berhubungan positif dengan jumlah rata-rata pengunjung per hari (yaitu, y akan meningkat dengan pertumbuhan ). Bentuk ketergantungan fungsional adalah linier.

Beras. 2.2. Scatterplot misalnya 2.2
Tabel 2.4
| t | x 2t | x 2t 2 | yt x 2t | x 1t x 2t |
| 8,25 | 68,0625 | 163,02 | 1,98 | |
| 10,24 | 104,8575 | 390,0416 | 3,1744 | |
| 9,31 | 86,6761 | 381,2445 | 5,1205 | |
| 11,01 | 121,2201 | 452,2908 | 5,2848 | |
| 8,54 | 72,9316 | 480,7166 | 6,6612 | |
| 7,51 | 56,4001 | 514,5101 | 7,3598 | |
| 12,36 | 152,7696 | 927,1236 | 11,6184 | |
| 10,81 | 116,8561 | 962,6305 | 13,0801 | |
| 9,89 | 97,8121 | 901,2757 | 12,7581 | |
| 13,72 | 188,2384 | 1252,0872 | 15,3664 | |
| 12,27 | 150,5529 | 1225,0368 | 15,8283 | |
| 13,92 | 193,7664 | 1511,016 | 20,7408 | |
| S | 127,83 | 1410,44 | 9160,9934 | 118,9728 |
| Rata-rata | 10,65 |
Secara umum, perlu untuk menentukan parameter model ekonometrik dua faktor
y t \u003d a 0 + a 1 x 1t + a 2 x 2t + t
Informasi yang diperlukan untuk perhitungan lebih lanjut disajikan pada Tabel. 2.4.
Mari kita perkirakan parameter model ekonometrika dua faktor linier menggunakan metode kuadrat terkecil.

Lewat sini,
Evaluasi koefisien = 61,6583 menunjukkan bahwa, dengan hal lain dianggap sama, dengan peningkatan area perdagangan sebesar 1 ribu m 2, omset tahunan akan meningkat rata-rata 61,6583 juta rubel.
Perkiraan koefisien = 2,2748 menunjukkan bahwa, hal lain dianggap sama, dengan peningkatan rata-rata jumlah pengunjung per 1.000 orang. per hari, omset tahunan akan meningkat rata-rata 2,2748 juta rubel.
Contoh 2.3. Menggunakan informasi yang disajikan dalam tabel. 2.2 dan 2.4, perkirakan parameter model ekonometrik faktor tunggal
![]()
di mana nilai terpusat dari omset tahunan toko ke-, juta rubel; - nilai terpusat dari rata-rata jumlah pengunjung harian ke toko ke-t, ribu orang. (lihat contoh 2.1-2.2).
Larutan. Informasi tambahan yang diperlukan untuk perhitungan disajikan dalam Tabel. 2.5.
Tabel 2.5
| -48,53 | -2,40 | 5,7720 | 116,6013 | |
| -30,20 | -0,41 | 0,1702 | 12,4589 | |
| -27,34 | -1,34 | 1,8023 | 36,7084 | |
| -27,21 | 0,36 | 0,1278 | -9,7288 | |
| -12,00 | -2,11 | 4,4627 | 25,3570 | |
| 0,22 | -3,14 | 9,8753 | -0,6809 | |
| 6,72 | 1,71 | 2,9156 | 11,4687 | |
| 20,76 | 0,16 | 0,0348 | 3,2992 | |
| 22,84 | -0,76 | 0,5814 | -17,413 | |
| 22,97 | 3,07 | 9,4096 | 70,4503 | |
| 31,55 | 1,62 | 2,6163 | 51,0267 | |
| 40,26 | 3,27 | 10,6766 | 131,5387 | |
| Jumlah | 48,4344 | 431,0566 |
Dengan menggunakan rumus (2.35), kita peroleh

Lewat sini,
![]()
http://www.cleverstudents.ru/articles/mnk.html
Contoh.
Data eksperimen tentang nilai-nilai variabel X dan pada diberikan dalam tabel. 
Sebagai hasil dari penyelarasannya, fungsi ![]()
Menggunakan metode kuadrat terkecil, perkiraan data ini dengan ketergantungan linier y=ax+b(temukan parameter sebuah dan b). Cari tahu mana dari dua garis yang lebih baik (dalam arti metode kuadrat terkecil) menyelaraskan data eksperimen. Membuat gambar.
Larutan.
Dalam contoh kita n=5. Kami mengisi tabel untuk kenyamanan menghitung jumlah yang termasuk dalam rumus koefisien yang diperlukan. 
Nilai pada baris keempat tabel diperoleh dengan mengalikan nilai baris ke-2 dengan nilai baris ke-3 untuk setiap angka saya.
Nilai pada baris kelima tabel diperoleh dengan mengkuadratkan nilai baris ke-2 untuk setiap angka saya.
Nilai kolom terakhir dari tabel adalah jumlah nilai di seluruh baris.
Kami menggunakan rumus metode kuadrat terkecil untuk menemukan koefisien sebuah dan b. Kami menggantinya dengan nilai yang sesuai dari kolom terakhir tabel: 
Akibatnya, y=0.165x+2.184 adalah garis lurus aproksimasi yang diinginkan.
Masih mencari tahu yang mana dari garis y=0.165x+2.184 atau ![]() lebih baik mendekati data asli, yaitu membuat perkiraan menggunakan metode kuadrat terkecil.
lebih baik mendekati data asli, yaitu membuat perkiraan menggunakan metode kuadrat terkecil.
Bukti.
Sehingga ketika ditemukan sebuah dan b fungsi mengambil nilai terkecil, perlu bahwa pada titik ini matriks bentuk kuadrat dari diferensial orde kedua untuk fungsi ![]() pasti positif. Mari kita tunjukkan.
pasti positif. Mari kita tunjukkan.
Diferensial orde kedua memiliki bentuk: 
Itu adalah
Oleh karena itu, matriks bentuk kuadrat memiliki bentuk 
dan nilai elemen tidak bergantung pada sebuah dan b.
Mari kita tunjukkan bahwa matriks tersebut pasti positif. Ini mensyaratkan bahwa sudut minor harus positif.
Minor sudut dari orde pertama  . Ketimpangannya ketat, karena poin
. Ketimpangannya ketat, karena poin
- pelajaran pengantar Bebas;
- Sejumlah besar guru berpengalaman (asli dan berbahasa Rusia);
- Kursus BUKAN untuk periode tertentu (bulan, enam bulan, tahun), tetapi untuk jumlah pelajaran tertentu (5, 10, 20, 50);
- Lebih dari 10.000 pelanggan yang puas.
- Biaya satu pelajaran dengan guru berbahasa Rusia - dari 600 rubel, dengan penutur asli - dari 1500 rubel
Inti dari metode kuadrat terkecil adalah dalam menemukan parameter model tren yang paling menggambarkan tren perkembangan beberapa fenomena acak dalam waktu atau ruang (tren adalah garis yang mencirikan tren perkembangan ini). Tugas metode kuadrat terkecil (OLS) adalah untuk menemukan tidak hanya beberapa model tren, tetapi untuk menemukan model terbaik atau optimal. Model ini akan optimal jika jumlah deviasi kuadrat antara nilai aktual yang diamati dan nilai tren yang dihitung terkait minimal (terkecil):
di mana adalah standar deviasi antara nilai aktual yang diamati
dan nilai tren terhitung yang sesuai,
Nilai aktual (yang diamati) dari fenomena yang diteliti,
Perkiraan nilai model tren,
Banyaknya pengamatan terhadap fenomena yang diteliti.
MNC jarang digunakan sendiri. Sebagai aturan, paling sering digunakan hanya sebagai teknik yang diperlukan dalam studi korelasi. Perlu diingat bahwa basis informasi LSM hanya dapat berupa rangkaian statistik yang dapat diandalkan, dan jumlah pengamatan tidak boleh kurang dari 4, jika tidak, prosedur pemulusan LSM dapat kehilangan akal sehatnya.
Toolkit OLS direduksi menjadi prosedur berikut:
Prosedur pertama. Ternyata apakah ada kecenderungan sama sekali untuk mengubah atribut yang dihasilkan ketika faktor-argumen yang dipilih berubah, atau dengan kata lain, apakah ada hubungan antara " pada " dan " X ».
Prosedur kedua. Ditentukan garis (lintasan) mana yang paling mampu menggambarkan atau mencirikan tren ini.
Prosedur ketiga.
Contoh. Misalkan kita memiliki informasi tentang hasil rata-rata bunga matahari untuk pertanian yang diteliti (Tabel 9.1).
Tabel 9.1
|
Nomor observasi |
||||||||||
|
Produktivitas, c/ha |
Karena tingkat teknologi dalam produksi bunga matahari di negara kita tidak banyak berubah selama 10 tahun terakhir, itu berarti, kemungkinan besar, fluktuasi hasil pada periode yang dianalisis sangat bergantung pada fluktuasi cuaca dan kondisi iklim. Apakah itu benar?
Prosedur MNC pertama. Hipotesis tentang adanya tren perubahan hasil bunga matahari tergantung pada perubahan kondisi cuaca dan iklim selama 10 tahun yang dianalisis sedang diuji.
Dalam contoh ini, untuk " kamu » disarankan untuk mengambil hasil bunga matahari, dan untuk « x » adalah jumlah tahun yang diamati dalam periode yang dianalisis. Menguji hipotesis tentang adanya hubungan antara “ x " dan " kamu » dapat dilakukan dengan dua cara: secara manual dan dengan bantuan program komputer. Tentunya dengan tersedianya teknologi komputer, masalah ini dapat teratasi dengan sendirinya. Namun, untuk lebih memahami toolkit OLS, disarankan untuk menguji hipotesis tentang adanya hubungan antara " x " dan " kamu » secara manual, saat hanya ada pena dan kalkulator biasa. Dalam kasus seperti itu, hipotesis keberadaan tren paling baik diperiksa secara visual dengan lokasi gambar grafis dari deret waktu yang dianalisis - bidang korelasi:


Bidang korelasi dalam contoh kita terletak di sekitar garis yang naik perlahan. Hal ini sendiri menunjukkan adanya tren tertentu dalam perubahan hasil bunga matahari. Tidak mungkin untuk berbicara tentang keberadaan tren apa pun hanya ketika bidang korelasi terlihat seperti lingkaran, lingkaran, awan yang benar-benar vertikal atau horizontal, atau terdiri dari titik-titik yang tersebar secara acak. Dalam semua kasus lain, perlu untuk mengkonfirmasi hipotesis adanya hubungan antara " x " dan " kamu dan melanjutkan penelitian.
Prosedur MNC kedua. Ditentukan garis (lintasan) mana yang paling mampu menggambarkan atau mengkarakterisasi tren perubahan hasil bunga matahari untuk periode yang dianalisis.
Dengan tersedianya teknologi komputer, pemilihan trend yang optimal terjadi secara otomatis. Dengan pemrosesan "manual", pilihan fungsi optimal dilakukan, sebagai suatu peraturan, secara visual - berdasarkan lokasi bidang korelasi. Artinya, menurut jenis bagan, persamaan garis dipilih, yang paling sesuai dengan tren empiris (ke lintasan sebenarnya).
Seperti yang Anda ketahui, di alam ada berbagai macam dependensi fungsional, sehingga sangat sulit untuk menganalisis secara visual bahkan sebagian kecil darinya. Untungnya, dalam praktik ekonomi nyata, sebagian besar hubungan dapat digambarkan secara akurat baik dengan parabola, atau hiperbola, atau garis lurus. Dalam hal ini, dengan opsi "manual" untuk memilih fungsi terbaik, Anda dapat membatasi diri hanya pada tiga model ini.
|
Hiperbola: |
||
|
|
|


Parabola orde kedua: ![]() :
:

Sangat mudah untuk melihat bahwa dalam contoh kita, tren perubahan hasil bunga matahari selama 10 tahun yang dianalisis paling baik dicirikan oleh garis lurus, sehingga persamaan regresi akan menjadi persamaan garis lurus.
Prosedur ketiga. Parameter persamaan regresi yang mencirikan garis ini dihitung, atau dengan kata lain, ditentukan formula analitik yang menggambarkan model tren terbaik.
Menemukan nilai parameter persamaan regresi, dalam kasus kami, parameter dan , adalah inti dari LSM. Proses ini direduksi menjadi penyelesaian sistem persamaan normal.
 (9.2)
(9.2)
Sistem persamaan ini cukup mudah diselesaikan dengan metode Gauss. Ingatlah bahwa sebagai hasil dari solusi, dalam contoh kami, nilai parameter dan ditemukan. Dengan demikian, persamaan regresi yang ditemukan akan memiliki bentuk sebagai berikut: ![]()
Ini banyak digunakan dalam ekonometrika dalam bentuk interpretasi ekonomi yang jelas dari parameternya.
Regresi linier direduksi untuk menemukan persamaan bentuk
atau
Ketik persamaan memungkinkan untuk nilai parameter yang diberikan X memiliki nilai teoretis dari fitur efektif, menggantikan nilai aktual faktor ke dalamnya X.
Membangun regresi linier turun ke memperkirakan parameternya sebuah dan di. Estimasi parameter regresi linier dapat ditemukan dengan metode yang berbeda.
Pendekatan klasik untuk memperkirakan parameter regresi linier didasarkan pada kuadrat terkecil(MNK).
LSM memungkinkan seseorang untuk mendapatkan perkiraan parameter seperti itu sebuah dan di, di mana jumlah deviasi kuadrat dari nilai sebenarnya dari sifat yang dihasilkan (y) dari terhitung (teoritis) minimal:
Untuk menemukan minimum suatu fungsi, perlu untuk menghitung turunan parsial terhadap masing-masing parameter sebuah dan b dan menyamakannya dengan nol.
Dilambangkan dengan S, maka:
Mengubah rumus, kami memperoleh sistem persamaan normal berikut untuk memperkirakan parameter: sebuah dan di:
Memecahkan sistem persamaan normal (3.5) baik dengan metode eliminasi berturut-turut variabel atau dengan metode determinan, kami menemukan perkiraan parameter yang diinginkan sebuah dan di.
Parameter di disebut koefisien regresi. Nilainya menunjukkan rata-rata perubahan hasil dengan perubahan faktor sebesar satu satuan.
Persamaan regresi selalu dilengkapi dengan indikator keketatan sambungan. Ketika menggunakan regresi linier, koefisien korelasi linier bertindak sebagai indikator tersebut. Ada berbagai modifikasi rumus koefisien korelasi linier. Beberapa dari mereka terdaftar di bawah ini:
Seperti yang Anda ketahui, koefisien korelasi linier berada dalam batas: -1 ≤ ≤ 1.
Untuk menilai kualitas pemilihan fungsi linier, kuadrat dihitung
Koefisien korelasi linier yang disebut koefisien determinasi. Koefisien determinasi mencirikan proporsi varians fitur efektif y, dijelaskan oleh regresi, dalam varians total dari sifat yang dihasilkan:
Dengan demikian, nilai 1 - mencirikan proporsi dispersi y, disebabkan oleh pengaruh faktor lain yang tidak diperhitungkan dalam model.
Pertanyaan untuk pengendalian diri
1. Inti dari metode kuadrat terkecil?
2. Berapa banyak variabel yang memberikan regresi berpasangan?
3. Koefisien apa yang menentukan ketatnya hubungan antara perubahan?
4. Dalam batas berapakah koefisien determinasi ditentukan?
5. Estimasi parameter b dalam analisis korelasi-regresi?
1. Christopher Dougherty. Pengantar ekonometrika. - M.: INFRA - M, 2001 - 402 hal.
2. S.A. Borodich. Ekonometrika. Minsk LLC "Pengetahuan Baru" 2001.
3. R.U. Rakhmetova Kursus singkat di bidang ekonometrika. Tutorial. Almaty. 2004. -78s.
4. I.I. Eliseeva.Ekonometrika. - M.: "Keuangan dan statistik", 2002
5. Informasi bulanan dan majalah analitis.
Model ekonomi nonlinier. Model regresi nonlinier. Konversi variabel.
Model ekonomi nonlinier..
Konversi variabel.
koefisien elastisitas.
Jika ada hubungan non-linier antara fenomena ekonomi, maka mereka dinyatakan menggunakan fungsi non-linier yang sesuai: misalnya, hiperbola sama sisi , parabola derajat kedua, dll.
Ada dua kelas regresi non-linier:
1. Regresi yang tidak linier terhadap variabel penjelas yang termasuk dalam analisis, tetapi linier terhadap parameter yang diestimasi, misalnya:
Polinomial berbagai derajat - , ;
Hiperbola sama sisi - ;
Fungsi semilogaritma - .
2. Regresi yang bersifat non-linier pada parameter yang diestimasi, misalnya:
Kekuasaan - ;
Demonstratif -;
Eksponensial - .
Jumlah total deviasi kuadrat dari nilai individu dari atribut yang dihasilkan pada dari nilai rata-rata disebabkan oleh pengaruh banyak faktor. Kami secara kondisional membagi seluruh rangkaian alasan menjadi dua kelompok: mempelajari faktor x dan faktor lain.
Jika faktor tersebut tidak mempengaruhi hasil, maka garis regresi pada grafik sejajar dengan sumbu oh dan
Kemudian seluruh dispersi dari atribut yang dihasilkan adalah karena pengaruh faktor lain dan jumlah total deviasi kuadrat akan bertepatan dengan residual. Jika faktor lain tidak mempengaruhi hasil, maka kamu terikat Dengan X secara fungsional, dan jumlah sisa kuadrat adalah nol. Dalam hal ini, jumlah deviasi kuadrat yang dijelaskan oleh regresi sama dengan jumlah kuadrat total.
Karena tidak semua titik bidang korelasi terletak pada garis regresi, pencarnya selalu terjadi karena pengaruh faktor X, yaitu regresi pada pada X, dan disebabkan oleh tindakan penyebab lain (variasi yang tidak dapat dijelaskan). Kesesuaian garis regresi untuk ramalan tergantung pada bagian mana dari total variasi sifat pada menjelaskan variasi yang dijelaskan
Jelas, jika jumlah deviasi kuadrat karena regresi lebih besar dari jumlah sisa kuadrat, maka persamaan regresi signifikan secara statistik dan faktor X memiliki dampak yang signifikan pada hasil. y.
, yaitu dengan jumlah kebebasan variasi independen fitur. Jumlah derajat kebebasan terkait dengan jumlah unit populasi n dan jumlah konstanta yang ditentukan darinya. Sehubungan dengan masalah yang diteliti, jumlah derajat kebebasan harus menunjukkan berapa banyak penyimpangan independen dari P
Penilaian signifikansi persamaan regresi secara keseluruhan diberikan dengan bantuan F- Kriteria Fisher. Dalam hal ini, hipotesis nol diajukan bahwa koefisien regresi sama dengan nol, yaitu. b= 0, dan karenanya faktor X tidak mempengaruhi hasil y.
Perhitungan langsung dari kriteria-F didahului dengan analisis varians. Pusatnya adalah perluasan jumlah total deviasi kuadrat dari variabel pada dari nilai rata-rata pada menjadi dua bagian - "dijelaskan" dan "tidak dijelaskan":
Jumlah total deviasi kuadrat;
Jumlah kuadrat deviasi dijelaskan oleh regresi;
Jumlah sisa deviasi kuadrat.
Setiap jumlah deviasi kuadrat terkait dengan jumlah derajat kebebasan , yaitu dengan jumlah kebebasan variasi independen fitur. Jumlah derajat kebebasan berhubungan dengan jumlah unit populasi n dan dengan jumlah konstanta yang ditentukan darinya. Sehubungan dengan masalah yang diteliti, jumlah derajat kebebasan harus menunjukkan berapa banyak penyimpangan independen dari P mungkin diperlukan untuk membentuk jumlah kuadrat tertentu.
Dispersi per derajat kebebasanD.
F-rasio (F-kriteria):
Jika hipotesis nol benar, maka faktor dan varians residual tidak berbeda satu sama lain. Untuk H 0, sanggahan diperlukan agar varians faktor melebihi residual beberapa kali. Ahli statistik Inggris Snedecor mengembangkan tabel nilai kritis F-hubungan pada tingkat signifikansi yang berbeda dari hipotesis nol dan jumlah derajat kebebasan yang berbeda. Nilai tabel F-kriteria adalah nilai maksimum rasio varians yang dapat terjadi jika mereka menyimpang secara acak untuk tingkat probabilitas tertentu dari kehadiran hipotesis nol. Nilai yang dihitung F-hubungan diakui andal jika o lebih besar dari tabel.
Dalam hal ini, hipotesis nol tentang tidak adanya hubungan fitur ditolak dan kesimpulan dibuat tentang signifikansi hubungan ini: F fakta > F tabel H0 ditolak.
Jika nilainya kurang dari tabel F fakta , F tabel, maka probabilitas hipotesis nol lebih tinggi dari tingkat tertentu dan tidak dapat ditolak tanpa risiko serius untuk menarik kesimpulan yang salah tentang adanya suatu hubungan. Dalam hal ini, persamaan regresi dianggap tidak signifikan secara statistik. N o tidak menyimpang.
Kesalahan standar dari koefisien regresi
Untuk menilai signifikansi koefisien regresi, nilainya dibandingkan dengan kesalahan standarnya, yaitu ditentukan nilai sebenarnya t-Tes siswa: yang kemudian dibandingkan dengan nilai tabel pada tingkat signifikansi tertentu dan jumlah derajat kebebasan ( n- 2).
Kesalahan Standar Parameter sebuah:
Signifikansi koefisien korelasi linier diperiksa berdasarkan besarnya kesalahan koefisien korelasi r:
Varians total dari sebuah fitur X:
Regresi Linier Berganda
Bangunan model
Regresi berganda adalah regresi fitur yang efektif dengan dua atau lebih faktor, yaitu model bentuk
Regresi dapat memberikan hasil yang baik dalam pemodelan jika pengaruh faktor lain yang mempengaruhi objek penelitian dapat diabaikan. Perilaku variabel ekonomi individu tidak dapat dikendalikan, yaitu, tidak mungkin untuk memastikan kesetaraan semua kondisi lain untuk menilai pengaruh satu faktor yang diteliti. Dalam hal ini, Anda harus mencoba mengidentifikasi pengaruh faktor lain dengan memasukkannya ke dalam model, yaitu membangun persamaan regresi berganda: y = a+b 1 x 1 +b 2 +…+b p x p + .
Tujuan utama dari regresi berganda adalah untuk membangun model dengan sejumlah besar faktor, sambil menentukan pengaruh masing-masing faktor secara individual, serta dampak kumulatifnya pada indikator yang dimodelkan. Spesifikasi model mencakup dua bidang pertanyaan: pemilihan faktor dan pilihan jenis persamaan regresi